概述
中文分词是自然语言处理中的核心任务,旨在将连续的中文文本分割为有意义的词语。不同于英文的空格分隔,中文需要依赖算法和语料库进行精准切分。
主要技术分类
基于规则的方法
依赖词典和语法规则(如最大匹配算法),适合结构化文本但泛化能力弱。统计模型方法
通过大规模语料训练概率模型(如隐马尔可夫模型),兼顾效率与准确性。深度学习方法
使用神经网络(如BiLSTM-CRF、Transformer)捕捉上下文语义,成为当前主流。
应用场景
- 社交媒体分析:精准分词助力情感识别与话题挖掘
- 机器翻译:分词质量直接影响翻译效果
- 智能问答:语义理解的基础环节
扩展阅读
欲了解更多关于HanLP算法实现细节,可访问:
HanLP_Algorithm_Details
[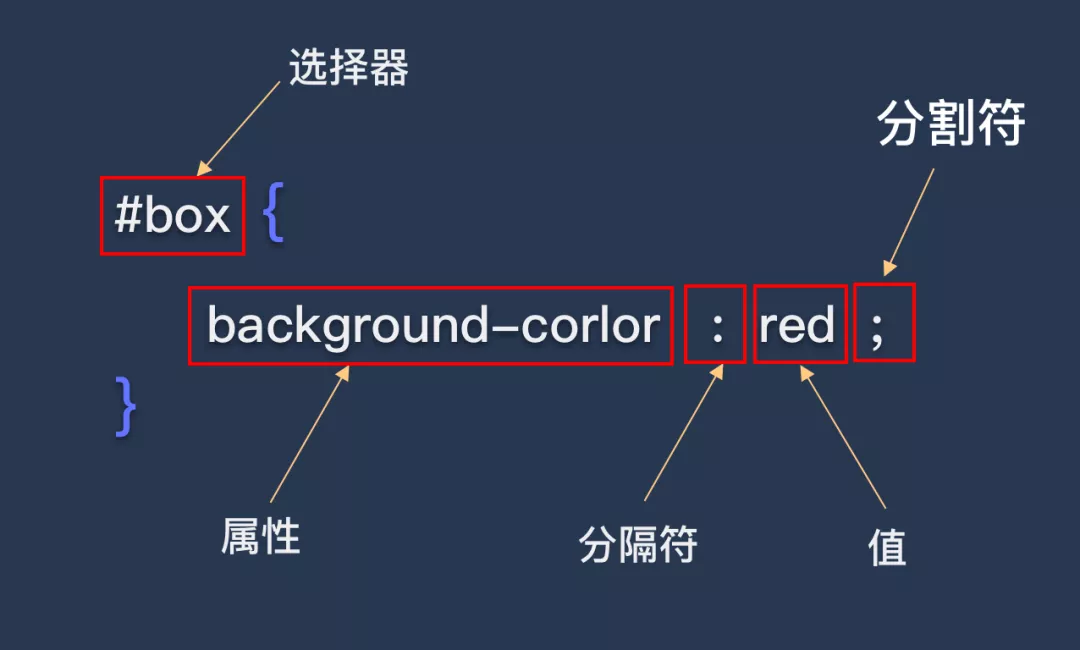]